
챗지피티(ChatGPT)는 인간이 던진 기본적인 질문을 이해하고, 언어를 다루는 능력 또한 상당함을 보여주고 있다. 이로 인해 사람들은 챗지피티가 인간 지식 전체를 학습하였고, 따라서 인간이 할 수 있는 많은 복잡한 작업들을 수행할 수 있을 것이라고 추정하게 되었다.
챗지피티와 같은 일반 대화형 대규모 언어 모델(LLM)의 기본 형태는 프로그램의 불완전성, 요청한 주제에 대한 그럴듯한 허구와 거짓 정보 제공(https://bit.ly/47ssZD3), 기본 수학에서의 한계(https://bit.ly/3RhD4xh) 등의 많은 문제를 보여주었다.
물론 빠른 속도로 진화하며 그 문제를 극복해가고 있기는 하다. 그렇다면 2023년 12월 현재를 기준으로 할 때 생성형 AI는 과연 연구 목적으로 활용가능한 것일까? 이 글에서는 결과의 사실적 정확성이 요구되는 연구용으로도 활용할 수 있을지에 대해 살펴보고자 한다. <지난호 박남기의 AI시대 교육법㉚에 이어 계속. 편집자>
나. 빙 AI(Bing AI)
마이크로소프트 빙 AI는 답변을 할 때 구체적으로 출처를 밝히는 방식을 취하고 있다. 그러나 출처를 확인해보면 펠리컨 망고에 대한 언급이 전혀 없다는 것을 알 수 있다. 두 번째 출처는 펠리컨 망고의 다른 이름인 카라바오 망고에 대해 논의하고, 세 번째와 네 번째 출처는 또 다른 이름인 마닐라 망고에 대해 언급하고 있다.
그러나 이 세 가지 모두에서 이 망고들이 생김새가 아닌 단맛에 대해 논의된 것을 볼 수 있다. 바드의 응답에서 나타난 펠리컨 망고의 생김새에 대한 유사한 오류가 여기에도 나타나고 있음을 볼 수 있다.

빙 AI가 생성한 내용 및 그 출처를 함께 제시하더라도, 당분간은 반드시 해당 사이트의 내용을 확인 후에 활용해야 한다. 그렇지 않으면 부정확한 내용, 혹은 출처에 없는 내용을 인용하게 될 수도 있다.
다. Perplexity AI
다음은 Perplexity AI가 질문에 대해 제공한 응답이다. 첫 번째 인용문이 마이크로소프트 빙 AI의 것과 같다는 것을 알 수 있습니다. Perplexity AI는 두 망고가 비슷한 생김새라고 특징 짓고 있어서 더 정확함을 알 수 있다. 그러나 이 AI는 펠리컨 망고에 대해 전혀 언급하지 않은 두 출처를 인용하고 있어, 어떻게 이러한 결정을 내렸는지 판단할 길이 없다.
또한, 제공한 이미지는 하든(Haden)이나 토미 앳킨스(Tommy Atkins) 망고를 닮은 적녹색 망고이다. Perplexity의 AI가 다른 AI보다 더 나은 응답을 한 것이 우연인지, 아니면 다른 훈련을 받아 더 나은 답을 했는지 알기 어렵다. 인용문을 바탕으로 판단할 때 우연일 가능성이 높아보인다.

- Perplexity의 Copilot
펄플렉시티의 최신 버전인 Perplexity Copilot을 통한 실험도 시도했다. 첫 시도에서는 응답을 내놓지 못했는데, 이는 OpenAI의 최근 DDoS 공격과 관련된 문제 때문일 가능성이 있다.
그래서 2023년 11월 12일에 다시 질문을 했고, 다음과 같은 답변을 받을 수 있었다. 기본 대화형 LLM보다 응답시간이 약간 더 오래 걸렸다.

Perplexity Copilot은 다른 AI와 달리 결과 생성을 위해 거친 단계를 보여준다. 위 그림의 질문(프롬프트) 바로 아래에 단계가 표시되어 있다. 우리는 이 AI가 "펠리컨 망고 특성," "샴페인 망고 특성," "펠리컨 망고 대 샴페인 망고 차이점" 검색을 시도했고, 최종 응답을 작성하기 전에 19개의 다른 출처를 검토했다는 것을 알 수 있다.
‘단계’표시 아래에 이 출처들이 나열되어 있다. Perplexity 기본 버전도 유사한 작업을 수행하지만 더 작은 규모다.
내놓은 결과를 평가해보면 다음과 같다. Perplexity Copilot도 여전히 거짓 답을 내놓고 있다. 세 번째 문장은 펠리컨 망고가 어윈 망고의 한 종류라고 말하는데, 이는 거짓이며 제시한 출처에도 나오지 않는다.
또한 관련 없는 정보인 펠리컨 망고가 미야자키 망고와 다르다는 점을 구체적으로 언급하고 있다. 이는 검색을 통해 펠리컨 망고에 대한 정보를 찾지 못하자 대신 내놓은 답일 가능성이 크다.
Perplexity Copilot은 펠리컨 망고의 물리적 특성에 대한 세부 정보를 찾지 못했다고 언급함으로써 AI 나름의 한계를 인정하고 있다. 샴페인 망고에 대해 더 많은 출처가 있기 때문에, 이에 대한 세부 정보는 정확하다는 것을 알 수 있다.
결론적으로, 어떤 검색 엔진 기반 대화형 LLM이든, 검색 엔진을 통해 빠르게 답을 찾을 수 없다면, 그 AI가 내놓은 결과는 그대로 받아들이기 어렵다는 것을 알 수 있다. 따라서 사용자는 자신이 배경 지식이 없는 정보에 대해 답을 구하고자 할 경우에는, 직접 후속 검색을 수행하여 LLM이 제공하는 결과를 검증해야 한다.
이러한 유형의 LLM을 사용하여 연구를 수행하고자 할 때에는 모든 경우에 이 원칙이 그대로 적용된다. 이번 실험결과를 토대로 볼 때, 넓은 주제에 대한 피상적인 이해 수준을 넘어서는 연구하고자 한다면, 아직은 이러한 유형의 LLM을 사용하지 않는 것이 바람직해 보인다.
5. 학술 논문 특화형 AI, Elicit과 Consensus
ChatGPT (구체적으로는 그 기반 생성 모델인 GPT)는 학술 논문을 비롯한 다양한 사이트 글을 통해 훈련되었지만, 출처를 제대로 인용하지 못하고, 출처를 요청할 경우 거짓 출처를 제시하는 경우가 많다. 앞에서 살펴본 것처럼 출처를 제공하는 대화형 LLM도 검색 엔진의 능력에 한계가 있다.
생성 AI가 제시하는 내용과 출처에 오류가 섞여 있는 현재의 상황에서는 연구에 그대로 활용하는 데에 한계가 많다. 제공된 내용의 사실 판단이 어려운 경우에는 해당 사이트나 관련 논문을 직접 찾아 확인하는 절차를 거친 후 활용해야 한다.
현재 상황에서 연구 진행 과정에서 생성 AI의 도움을 받을 수 있는 생산적인 방법은 학술 논문과 텍스트를 검색할 때, 혹은 논문을 요약하고 분석하는 데 특화된 AI 도구를 활용하는 것이다.
가. Elicit
Elicit(https://elicit.com/)은 연구자들이 학술 논문을 통해 원하는 답을 구할 수 있도록 만들어진 LLM이다. Elicit은 연구자가 원하는 학술논문 검색, PDF 파일에서 자료 추출- 학술 논문 PDF를 업로드한 후 이를 요약하고 분석-, 그리고 논문들을 바탕으로 학문적 핵심 개념 정리 등을 할 수 있다.
Elicit에게 “Generative AI 시대 간호교육이 직면할 과제와 나아가야할 방향”을 입력한 결과 다음과 같은 답을 얻었다. 보는 것처럼 관련 논문을 검색하여 상위 4개의 초록을 요약한 후 최종 답변을 제시해줌을 알 수 있다. 이를 선행연구 분석에 활용하면 보탬이 될 것이다.
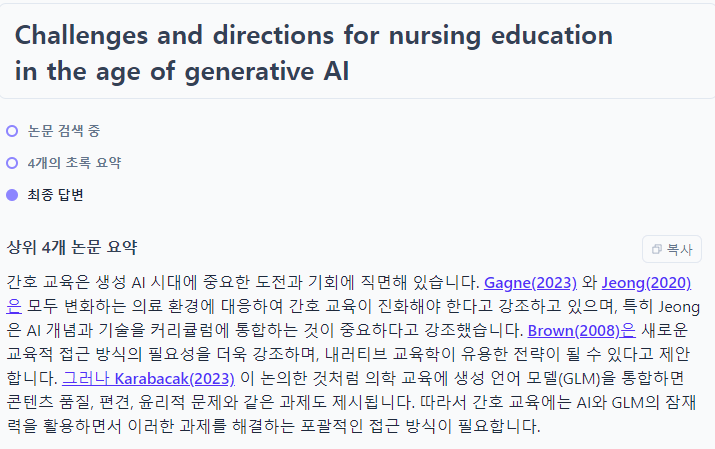
Elicit은 스스로 특정 사실을 집계하여 제시하는 역할은 하지 못한다(예: 2020년 중동이 소비한 초콜릿의 양은 얼마인가요?). 그리고 비실증적 연구에도 활용하기 어렵다.
계정을 만들면 5,000개의 무료 크레딧이 주어지며, 요청의 복잡성에 따라 크레딧이 소모되는데, 다 사용한 후에는 구독을 해야만 더 많은 크레딧을 받을 수 있다.
나. Consensus
Consensus(https://consensus.app/)는 LLM 기술을 활용하여 검색어와 관련된 연구 텍스트 목록을 생성한다는 점에서 Elicit과 유사하다. 그러나 Elicit과 달리 Consensus는 논문이 얼마나 많이 인용되었는지, 문헌 고찰인지, 관찰 연구인지 등 논문에 대한 기본적인 사실도 함께 제시해준다.
또한 Consensus는 사용자가 입력한 질문 프롬프트에 대해 얼마나 많은 연구가 긍정, 부정 또는 불확정인지에 대한 통계도 제공해준다. Consensus 기본형은 무료이며, 찾은 논문 중에서 요약은 상위 10개, 집계는 상위 20개에 대해서만 제공해준다.
더 강력한 기능은 한 달에 20회만 이용할 수 있다. 유료인 프리미엄형은 기능을 무제한으로 사용할 수 있고, 보다 완벽한 요약 기능도 제공한다. Consensus는 아직 베타 버전으로 세부 사항은 지속적으로 변경될 것으로 보인다. 다음 그림은 질문과 그에 대한 답이다.
질문: How can we use Generative AI for nursing education?
답: 상위 10개 논문은 새로운 평가 프레임워크, 챗봇, AI 기반 의료 기술을 통해 기술과 지식을 향상하고, 간호 및 직업적 관계를 개선하며, 학생의 학습을 지원하는 방식으로 간호교육에 활용할 수 있음을 시사해준다.
이처럼 Consensus를 활용하면 연구자가 가지고 있는 질문에 대해 기존 논문들이 제시하는 답을 얻을 수 있다.

이 글에서 열거한 도구들은 사용자가 명령 혹은 질문을 하면, 관련된 학술 논문을 검색하고, 연구자가 원하는 요약 및 분석 등을 해준다.
기존의 구글 스콜라(https://scholar.google.com)도 구글의 검색 색인 알고리즘을 기반으로 관련된 논문 리스트를 제공하는 기능은 수행하고 있다. 여기에 소개한 도구들은 연구자에게 보탬이 되는 추가 기능을 수행하는 점에서 차이를 보인다.
6. 결론
대화형 LLM 기반 연구용 기존 도구들을 보면, 지능형 대화 수준에서 연구자와 상호 작용하기 위해서는 아직 갈 길이 멀다. 아직까지는 ChatGPT, 바드, 빙 AI 등을 이용해 연구에 필요한 데이터나 이론을 얻는 것은 극히 위험하다.
연구 전용 생성 AI를 활용할 경우에는 그 위험성이 조금 줄어든다. 일반 생성 AI를 활용하고자 할 경우에는 반드시 제공된 내용의 출처를 찾아 확인하는 절차를 거쳐야 한다.
철저히 검증하지 않은 채 AI가 제공한 내용을 그대로 활용한 연구물을 학술지에 기고할 경우, 전문성을 가진 논문 심사자가 세밀하게 검토하지 않는 한 오류를 식별해내기 어려울 수 있다.게재된 후에라도 오류가 발견되면 당연히 연구자가 책임을 지겠지만, 그러한 사례가 증가하면 이는 학술지의 권위를 손상하게 될 것이다.
이러한 문제를 완화하기 위해서 학술단체들은 연구 진행과정에서 AI 활용 허용 범위, 활용시 이를 밝히는 방식 등에 대해 구체적으로 지침을 만들어 제시해야 할 것이다.
머지않아 대화형 LLM은 기존 논문을 심층적으로 분석하고, 거기에서 정보를 추출할 수 있게 발전될 것이다. 연구 특화 AI는 궁극적으로 방대한 학술 논문과 지식을 검토하여 연구자의 연구를 돕는 지능형 연구 지원 도구가 될 것으로 기대한다.
그리되면 연구 진행 과정에서 기존 연구들을 찾아 요약하고 통합 분석하는 데 들이는 시간과 에너지는 크게 줄어들 것이다. 대학 구성원들의 연구 및 교육 활동을 지원하기 위해 대학 도서관이 학술저널 데이터베이스를 구독하듯이, 머지않아 분야별 연구에 특화된 다양한 생성 AI (대화형 LLM)를 구독할 것으로 예상된다.

그래도 삭제하시겠습니까?
댓글을 남기실 수 있습니다.